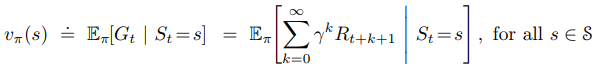강화학습 Sutton [Ch3 Finite Markov Decision Processes] #5 Policies and Value Functions
Policies and Value Functions 가치 함수(value function)란 주어진 상태(state) 또는 상태에 따른 행동(action)이 에이전트(agent)에게 있어 얼마나 좋은지 추측(estimate)하는 함수로, 정확하게는 에이전트가 앞으로 얼마나 보상을 받을지 (expected return)를 표현하는 함수이다. 이 보상들은 행동에 의해 받는 것이며, 특정한 방법으로 행동을 결정하는데 이를 정책(policy)라 한다. 어떤 상태가 입력으로 주어지면 행동을 선택할 확률을 반환하는 함수이다. 이를 $\pi$라 표현하며, $t$ 시점일 때 상태 $s$에서 행동 $a$를 할 확률은 $\pi(a|s)$이라할 수 있다. 상태 가치 함수 (state-value function) 어떤 정책 ..