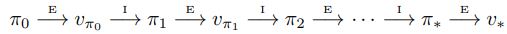강화학습 Sutton [Ch4 Dynamic Programming] #3 Policy Iteration
Policy Iteration 이전에 어떤 정책 $\pi$에 대한 가치 $v_\pi$ 구해서 이를 통해 개선했었다. 그리고 다시 개선된 정책 $\pi'$을 가지고 가지고 가치 $v_\pi'$를 판단하고 개선하고...새로운 정책은 확실히 이전 정책보다 좋으며, 유한한(finite) MDP에서 유한한 수의 정책을 사용하기 때문에, 결국 유한한 반복으로 결국 최적의 가치와 정책에 수렴한다. 이 때 $\xrightarrow{\text{E}}$는 정책 평가(policy evaluation)를, $\xrightarrow{\text{I}}$는 정책 개선(policy improvement)를 의미한다. 이러한 방법으로 정책을 찾는 과정을 policy iteration이라 한다.