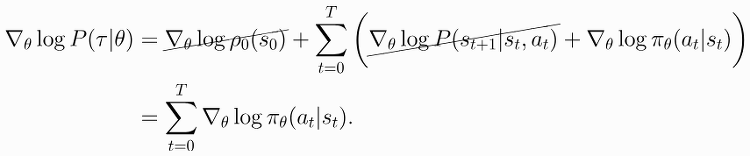OpenAI Spinning UP 번역] Proximal Policy Optimization
2019.05.21 해석 자연스럽게 수정 Proximal Policy Optimization 배경지식 (Background) 빠르게 알고갈 사실 (Quick Facts) 주요 방정식 (Key Equations) 탐험 vs 활용 (Exploration vs. Exploitation) 의사 코드 (Pseudo code) Proximal Policy Optimization배경지식 (Background)PPO는 현재 가지고 있는 데이터로 성능을 떨어뜨리지 않으면서 정책을 개선시키는 step을 가능한 멀리 밟도록하려면 어떻게 해야하는 지에 대해 고민했다는 점에서 TRPO와 같습니다. TRPO는 복잡한 2차 근사(second-order) 방법으로 해결했다면, PPO는 이전 정책과 새로운 정책이 가깝게 유지하도록 약..