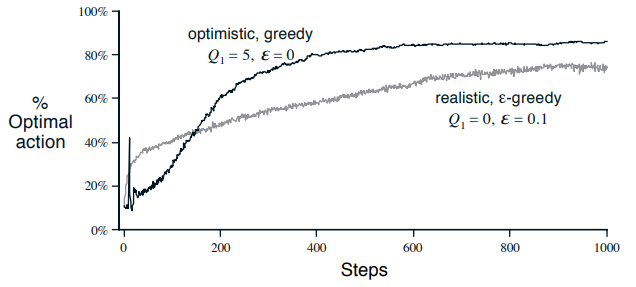
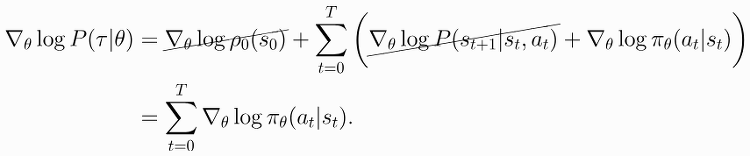강화학습 sutton ch2 Multi-armed Bandit] #4 Optimistic Initial Values 이전까지 다룬 모든 방법(sample-average, weight average 등)은 초기에 추측한 행동 가치 $Q_1(a)$에 따라 달라진다. 통계학에서는 이를 biased(편향되었다)라고 말한다. sample-average같은 경우 모든 행동의 경우가 최소 한번 나왔다면 bias는 없지만 상수 $\alpha$ 방법은 계속 남아 있다. 이런 bias로 인해 사용자가 정해줘야 하는 부분이 되기는 하지만 원하는 수준의 보상을 얻기 위한 사전지식으로 쉽게 줄 수 있다. 또는 exploration을 하도록 만드는 효과가 있다. 저번에 10-armed testbed를 다시 떠올려보자. 만약 초기 추측값을 모두 +5로 맞추면 보상이 어떻게 나오든 5보다 작아서 하지.. Sutton Books/Sutton 노트 6년 전
Ch2. Multi-armed Bandit (1) A k-armed Bandit Problem 이 글은 Richard S. Sutton과 Andrew G. Barto의 Reinforcement Learning: An Introduction second edition을 기반으로 하고 있습니다. 개인적인 주관과 지식으로 인해 틀린 내용이 있을 수 있으므로 피드백이나 질문은 언제나 환영입니다. P.S. 1장은 강화학습에 대한 소개이기 때문에 생략했다. Part I: Tabular Solution Methods Part I에서 다루는 강화학습은 상태와 행동의 수가 작아서 가치 함수를 배열(array)이나 테이블(table) 형태로 나타내어 문제를 푼다. 그렇기에 정확하게 최적의 가치함수와 정책을 구할 수 있다. 하지만 상태와 행동의 수가 큰 문제의 경우에는 사용할 수 없는 방법이다. 따라서 Part 2에.. Sutton Books/Sutton 노트 6년 전
OpenAI Spinning Up 번역] Part 3: 정책 최적화 소개(Intro to Policy Optimization) Welcome to Spinning Up in Deep RL! 원본은 Part 3: Intro to Policy Optimization OpenAI Spinning Up 번역] Part 1: 강화학습 핵심 개념(Key Concepts in RL) OpenAI Spinning Up 번역] Part 2: 강화학습 알고리즘 종류(Kinds of RL Algorithms) OpenAI Spinning Up 번역] Part 3: 정책 최적화 소개(Intro to Policy Optimization) Table of Contents Part 3: Intro to Policy Optimization Deriving the Simplest Policy Gradient Implementing the Simplest Po.. Online Tutorials/OpenAI Spinnig Up 6년 전
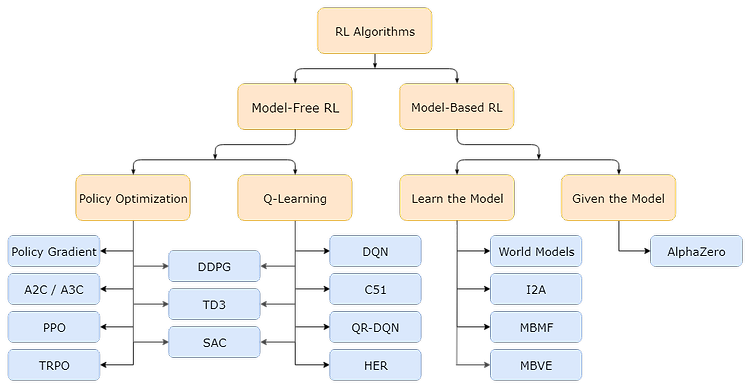
OpenAI Spinning Up 번역] Part 2: 강화학습 알고리즘 종류 Welcome to Spinning Up in Deep RL! 원본은 Part 2: Kinds of RL Algorithms OpenAI Spinning Up 번역] Part 1: 강화학습 핵심 개념(Key Concepts in RL) OpenAI Spinning Up 번역] Part 2: 강화학습 알고리즘 종류(Kinds of RL Algorithms) OpenAI Spinning Up 번역] Part 3: 정책 최적화 소개(Intro to Policy Optimization) Table of Contents Part 2: Kinds of RL Algorithms A Taxonomy of RL Algorithms Links to Algorithms in Taxonomy 이제까지 강화학습 용어와 표기법에.. Online Tutorials/OpenAI Spinnig Up 6년 전
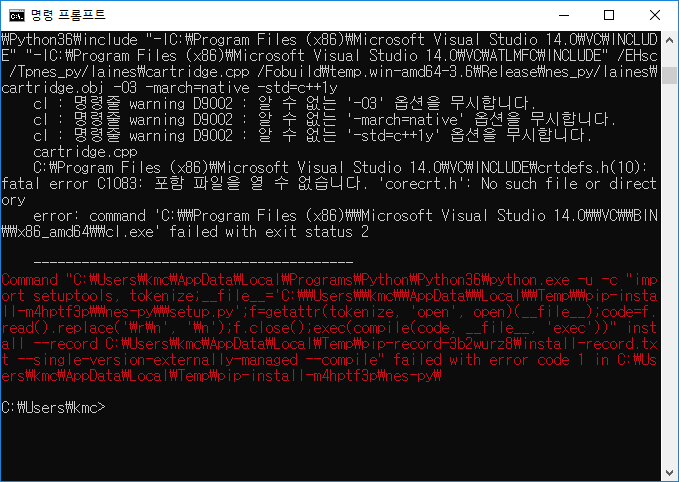
Windows 10에서 Mario 환경 설치 마리오 강화학습 할끄야! 강화학습 DQN과 A3C를 BreakoutDeterministic-v4만 하다보니 슬슬 지겨워지려던 참이였다. 그래서 다들 마리오를 많이 하길래 나도 도전!! 만약 그 전에 gym 설치를 하지 않은 사람은 여기 포스트를 참조. Mario 설치 다음과 같이 하면 마리오가 설치된다. pip install gym-super-mario-bros 물론 여기까지 쉽게 되면 내가 이런 글을 쓰지도 않았겠지 nes-py 설치문제 다른사람은 어떨지 몰라도 나는 nes-py에서 어떤 문제가 생겼는데 corecht.h가 없다는 문제였다. 내가 글을 쓰는 현재(2018-12-10) visual studio 2017이 최신이며 community를 설치했는데 그러면 visual studio install.. Project/환경설정 6년 전
강화학습 공부 자료 정리 강화학습 공부를 하기위해서 매번 찾아야하는 번거로움을 줄이기 위해 자료들을 모아놓기로 했다. Online Tutorial(Video) 기본적인 개념 뿐만 아니라 강화학습과 관련된 영상들을 정리하였다. 김성훈 교수님의 모두를 위한 RL강좌 팡요랩의 강화학습의 기초 이론 김태훈님의 알아두면 쓸데있는 신기한 강화학습 이웅원님의 RLCode와 A3C 쉽고 깊게 이해하기 곽동현님의 Introduction of Deep Reinforcement Learning David silver님의 RL Course David Silver님의 UCL Course on RL Berkely CA의 Deep RL Bootcamp UC Berkeley의 CS294-112 CS 8803 - Reinforcement Learning (G.. Project/환경설정 6년 전