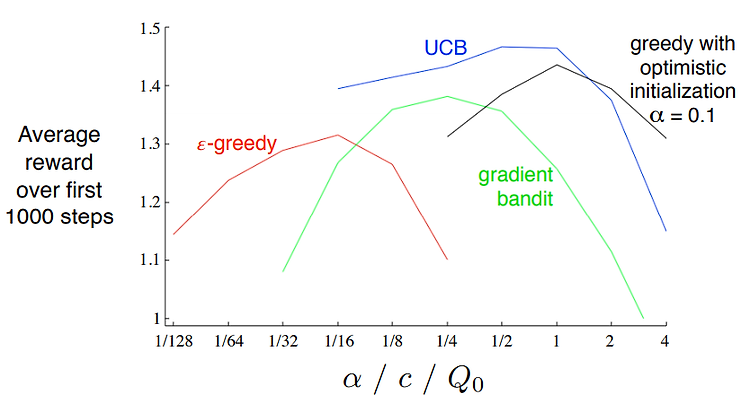
강화학습 sutton ch2 Multi-armed Bandit] #6
Associative Search (Contextual Bandits) 지금까지 다루었던 것은 nonassociative tasks, 즉 행동과 상황이 어떤 관련이 있을 필요가 없었다. stationary, nonstationary이던간에 그저 하나의 최고 행동을 하면 그만이였다. 하지만 실제 강화학습 문제는 그리 단순하지 않고 하나 이상의 상황이 존재할 것이다. 상황에 따라 행동을 결정해야 하는, 즉 정책(policy)을 학습시켜야 한다. 예를 들면, 이전에 n-armed bandit task가 플레이할 때마다 보상의 분포가 다 임의로 달라진다면? 왠만해서는 이전 방법으로 풀 수가 없다. 대신, 어떻게 바뀌었는지를 알 수 있게 슬롯 머신의 색깔이 변한다면? 그 슬롯 색깔에 따라 행동을 결정할 수 있을 ..