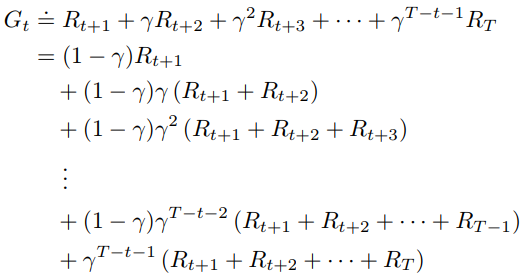강화학습 Sutton [Ch5 Dynamic Programming] #8 *Discounting-aware Importance Sampling
지금까지 봐왔던 Off-policy는 importance-sampling weight를 discount return에 곱하는 식으로 했었다. 그런데 이것은 discounted rewards의 합이라는 내부 구조를 고려하지 않고 그저 return 하나로만 생각했다. 이렇게 하면서 생기는 문제는 분산이 늘어난다는 것이다. 예를 들어, 에피소드가 길고 $\gamma$가 1보다 많이 작다고 생각해보자. 그냥 정확하게 에피소드가 100이고, $\gamma=0$이라고 하자. 첫 번째 time step에서 return은 $G_0=R_1$이지만, importance sampling ratio는 100개 $\frac{\pi(A_0|S_0)}{b(A_0|S_0)}\frac{\pi(A_1|S_1)}{b(A_1|S_1)}\c..