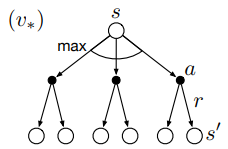
강화학습 Sutton [Ch3 Finite Markov Decision Processes] #6 Optimal Policies and Optimal Value Functions Optimal Policies and Optimal Value Functions 강화학습 문제를 해결한다는 말은 단순히 말하자면 보상을 많이받도록 하는 정책을 찾는다는 뜻이다. 그럼 더 좋은 정책이란 무엇일까? 다시말해, 현재 정책($\pi$)이 이전 정책($\pi'$)보다 좋다는 것은 어떻게 결정할 수 있을까? finite MDP에서 가치함수를 통해 다음과 같이 말할 수 있다. 모든 상태($s \in \mathcal{S}$)에서 이전 정책의 가치보다 현재 정책의 가치가 더 높거나 같다면($v_\pi(s) \ge v_{\pi'}(s)$), 현재 정책이 이전 정책보다 좋다.($\pi \ge \pi'$) 분명 가장 좋은 정책이 최소한 하나는 있을 것이다. 이를 최적의 정책(optimal policy)이라 하.. Sutton Books/Sutton 노트 6년 전