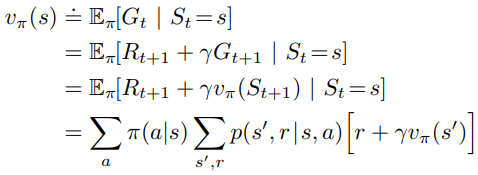강화학습 Sutton [Ch4 Dynamic Programming] #1 Policy Evaluation (Prediction)
Dynamic Programming Dynamic programming (DP)란 MDP같은 환경의 완벽한 모델을 가지고 최적의 정책을 계산하는 알고리즘들을 말한다. 이전처럼 수식 전체를 한 번에 계산하지 않기에 계산량이 좀 더 적다는 장점이 있다. 하지만 환경을 완전히 알아야 하는 단점이 있기에, 실제로 잘 사용하지는 않는다. 앞으로 나올 강화학습 알고리즘들은 정확한 계산을 하는 이 알고리즘만큼 효과를 보도록 근사하는 것이라 볼 수 있다. 상태, 행동 그리고 보상이 유한하게 존재하고 dynamic $p(s', r | s, a)$이 주어져서 알고있는 episodic finite MDP라 가정한다. (물론 continuous 경우에도 DP를 적용할 수는 있다. 상태화 행동을 양자화해서 finite-stat..