강화학습 sutton ch2 Multi-armed Bandit] #4
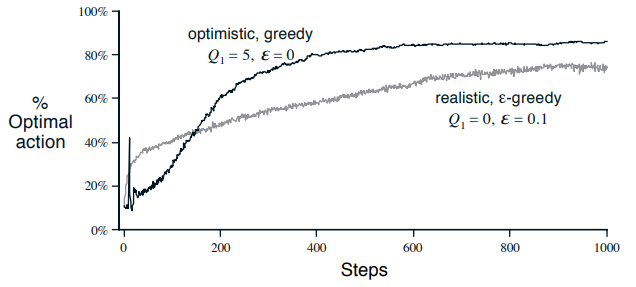
Optimistic Initial Values 이전까지 다룬 모든 방법(sample-average, weight average 등)은 초기에 추측한 행동 가치 $Q_1(a)$에 따라 달라진다. 통계학에서는 이를 biased(편향되었다)라고 말한다. sample-average같은 경우 모든 행동의 경우가 최소 한번 나왔다면 bias는 없지만 상수 $\alpha$ 방법은 계속 남아 있다. 이런 bias로 인해 사용자가 정해줘야 하는 부분이 되기는 하지만 원하는 수준의 보상을 얻기 위한 사전지식으로 쉽게 줄 수 있다. 또는 exploration을 하도록 만드는 효과가 있다. 저번에 10-armed testbed를 다시 떠올려보자. 만약 초기 추측값을 모두 +5로 맞추면 보상이 어떻게 나오든 5보다 작아서 하지..