강화학습 Sutton [Ch3 Finite Markov Decision Processes] #1 The Agent–Environment Interface
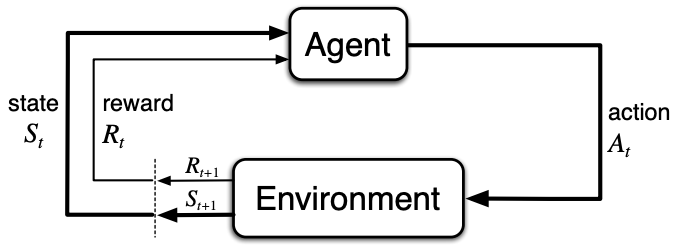
chapter 3부터는 가장 최신 edtion으로!! 알고보니 더 최신 버전이 있었다..난 옛날 버전을 하고 있었고 그러다보니 페이지도 다르기 때문에, 약간 수식면에서 다르지만...그냥 여기서부터 새로 시작하는 마음으로 해야지..어차피 이전은 그냥 느낌만 알면 됐어!!하핳! The Agent-Environment Interface MDP(Markov Decision process)는 강화학습에서 어떤 목표를 위해 순차적으로 행동을 결정(sequential decision making)을 해야하는 문제를 수식적으로 나타낸 것이다. 이 때 학습 또는 행동 결정자를 에이전트(agent). 에이전트와 상호작용하는 에이전트 외에 모든 것을 환경(environment)이라 한다. 이 둘은 서로 상호작용(intera..